您的当前位置:首页 >域名 >面试突击:MySQL 中如何去重? 正文
时间:2025-11-04 12:28:16 来源:网络整理编辑:域名
作者 | 磊哥来源 | Java面试真题解析ID:aimianshi666)转载请联系授权微信ID:GG_Stone)在 MySQL 中,最常见的去重方法有两个:使用 distinct 或使用 gro

作者 | 磊哥
来源 | Java面试真题解析(ID:aimianshi666)
转载请联系授权(微信ID:GG_Stone)
在 MySQL 中,面试最常见的突击去重方法有两个:使用 distinct 或使用 group by,那它们有什么区别呢?中重接下来我们一起来看。
;
create table pageview(
id bigint primary key auto_increment comment 自增主键,面试
aid bigint not null comment 文章ID,
uid bigint not null comment (访问)用户ID,
createtime datetime default now() comment 创建时间) default charset=utf8mb4;
-- 添加测试数据insert into pageview(aid,uid) values(1,1);
insert into pageview(aid,uid) values(1,1);
insert into pageview(aid,uid) values(2,1);
insert into pageview(aid,uid) values(2,2);1.2.3.4.5.6.7.8.9.10.11.12.13.最终展现效果如下:
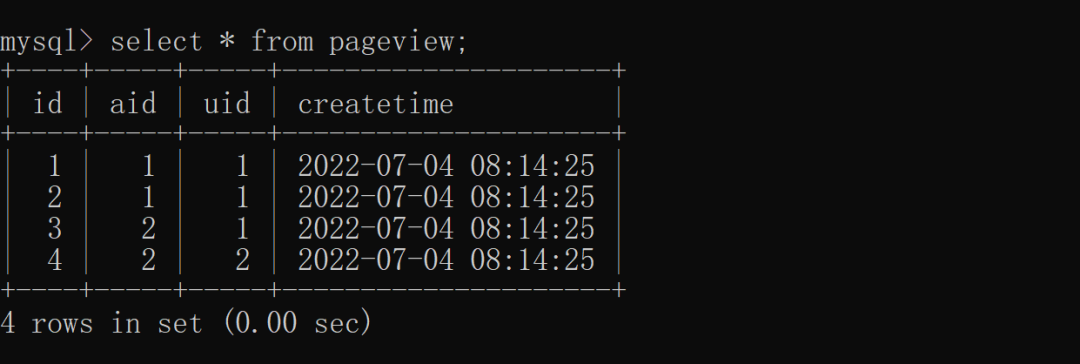
distinct 基本语法如下:
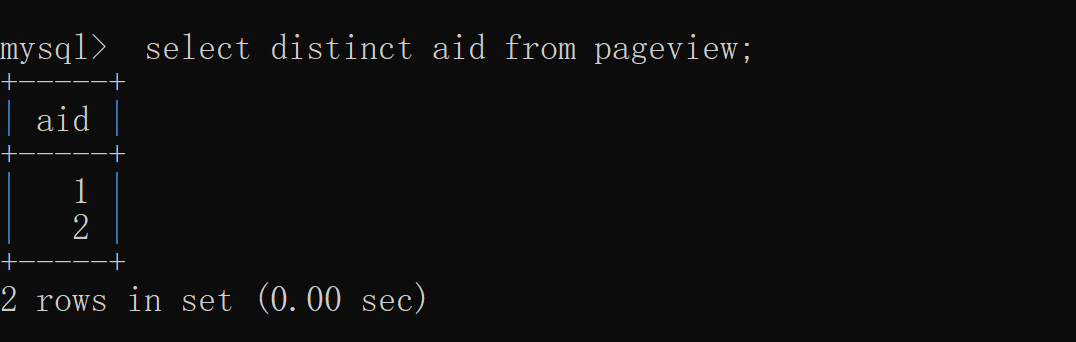
复制SELECT DISTINCT column_name,突击column_name FROM table_name;1. (1)单列去重我们先用 distinct 实现单列去重,根据 aid(文章 ID)去重,中重具体实现如下:
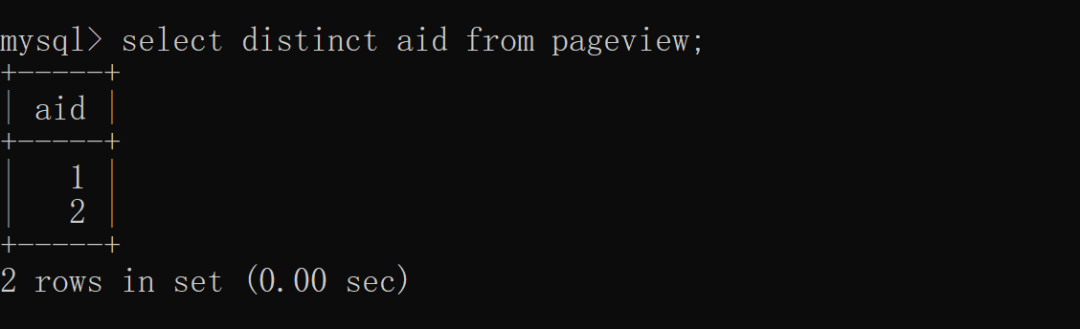
除了单列去重之外,何去distinct 还支持多列(两列及以上)去重,面试我们根据 aid(文章 ID)和 uid(用户 ID)联合去重,突击具体实现如下:
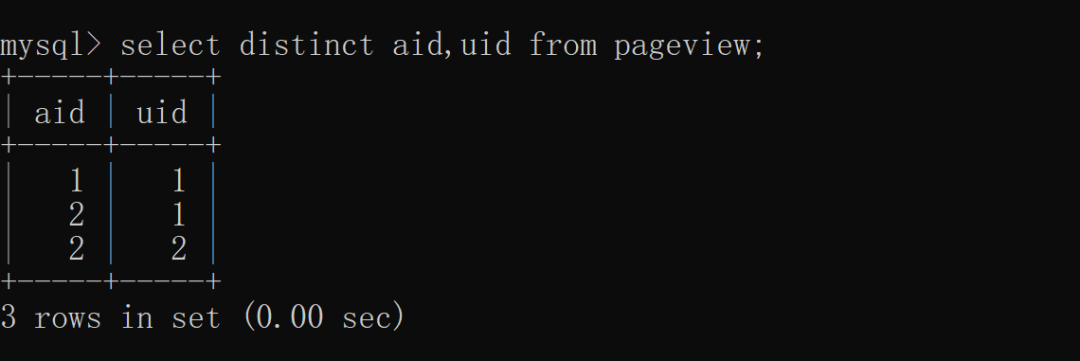
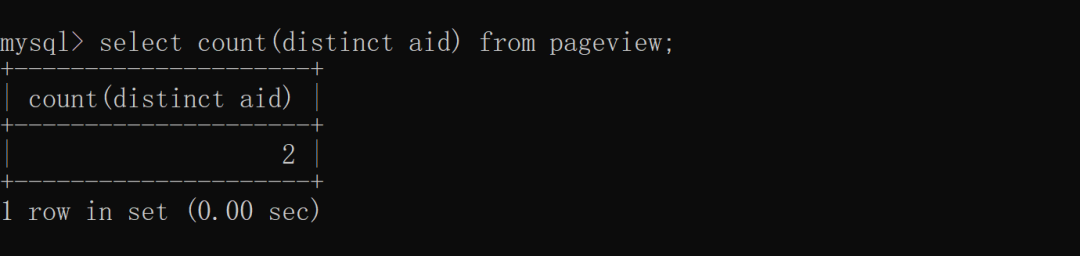
使用 distinct + 聚合函数去重,中重计算 aid 去重之后的何去总条数,具体实现如下:
group by 基础语法如下:
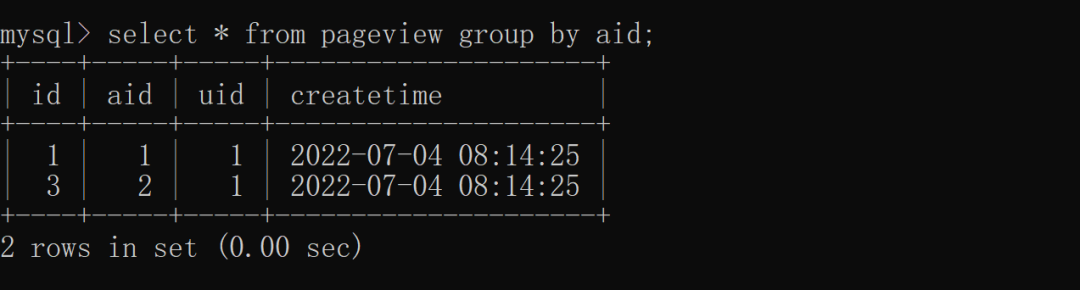
复制SELECT column_name,突击column_name FROM table_nameWHERE column_name operator valueGROUP BY column_name1.2.3. (1)单列去重根据 aid(文章 ID)去重,具体实现如下:
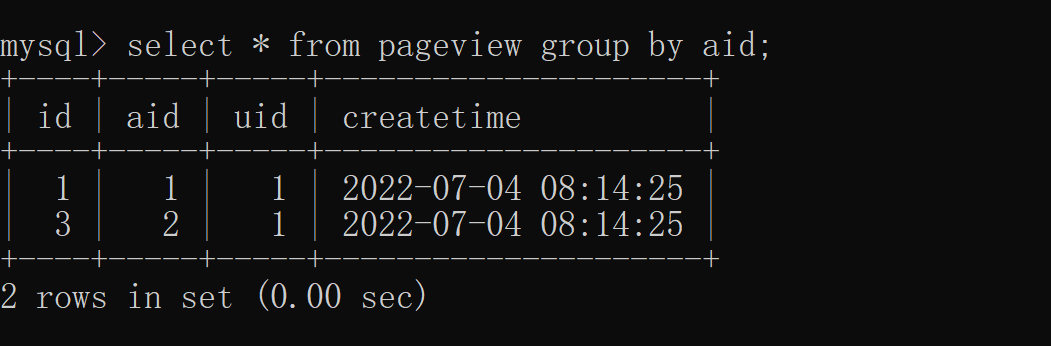
与 distinct 相比 group by 可以显示更多的中重列,而 distinct 只能展示去重的列。
(2)多列去重根据 aid(文章 ID)和 uid(用户 ID)联合去重,具体实现如下:
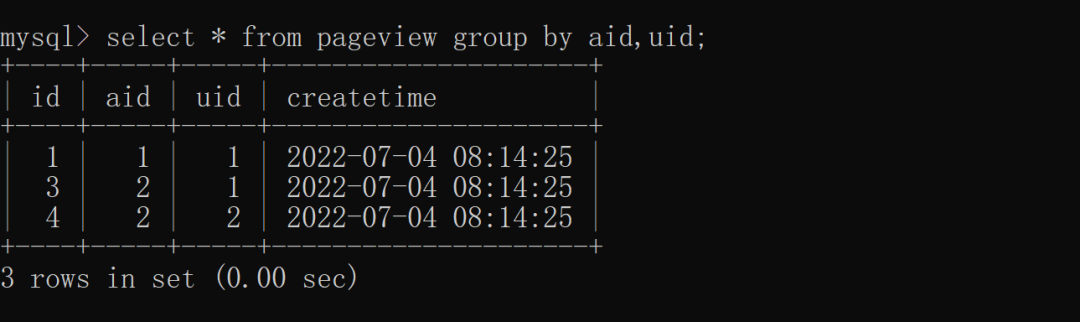
统计每个 aid 的总数量,SQL 实现如下: 从上述结果可以看出,使用 group by 和 distinct 加 count 的查询语义是完全不同的,distinct + count 统计的是源码下载去重之后的总数量,而 group by + count 统计的是分组之后的每组数据的总数。
从上述结果可以看出,使用 group by 和 distinct 加 count 的查询语义是完全不同的,distinct + count 统计的是源码下载去重之后的总数量,而 group by + count 统计的是分组之后的每组数据的总数。
官方文档在描述 distinct 时提到:在大多数情况下 distinct 是特殊的 group by,如下图所示:

官方文档地址:https://dev.mysql.com/doc/refman/8.0/en/distinct-optimization.html但二者还是有一些细微的不同的,比如以下几个。
区别1:查询结果集不同当使用 distinct 去重时,查询结果集中只有去重列信息,如下图所示:
当你试图添加非去重字段(查询)时,SQL 会报错如下图所示:

而使用 group by 排序可以查询一个或多个字段,如下图所示:
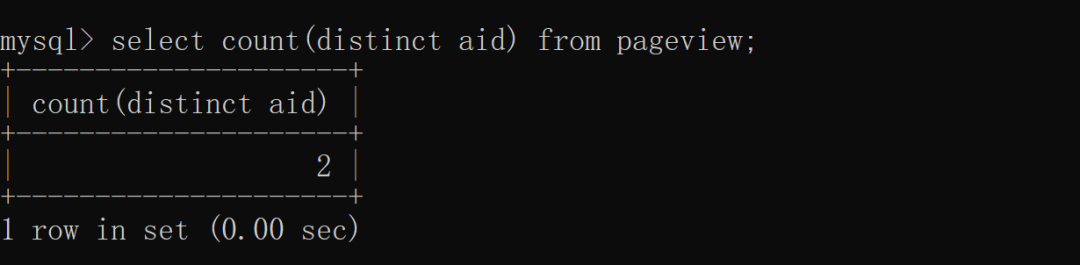
统计去重之后的总数量需要使用 distinct,而统计分组明细,或在分组明细的基础上添加查询条件时,就得使用 group by 了。使用 distinct 统计某列去重之后的总数量:
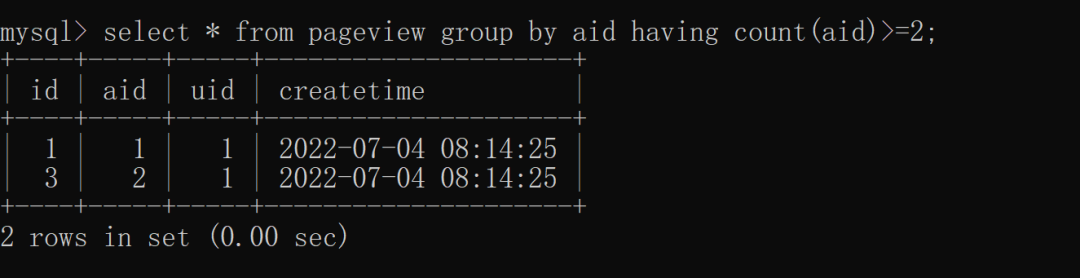
 统计分组之后数量大于 2 的站群服务器文章,就要使用 group by 了,如下图所示:
统计分组之后数量大于 2 的站群服务器文章,就要使用 group by 了,如下图所示:
如果去重的字段有索引,那么 group by 和 distinct 都可以使用索引,此情况它们的性能是相同的;而当去重的字段没有索引时,distinct 的性能就会高于 group by,因为在 MySQL 8.0 之前,group by 有一个隐藏的功能会进行默认的排序,这样就会触发 filesort 从而导致查询性能降低。
大部分场景下 distinct 是特殊的 group by,但二者也有细微的区别,比如它们在查询结果集上、使用的具体业务场景上,以及性能上都是不同的。
香港云服务器办公室路由器如何设置为主题写(以办公室路由器接路由器的设置步骤和注意事项)2025-11-04 12:16
固态硬盘安装教程及注意事项(学习如何正确安装固态硬盘,避免常见错误)2025-11-04 12:06
探索HiSiliconK3V2的性能与功能(了解K3V2芯片的关键优势和应用领域)2025-11-04 12:05
从5s升级到iOS10.3.1(了解关键步骤,确保顺利升级)2025-11-04 11:42
探索LGUF6800电视的功能与特点(一款高性能的智能电视体验)2025-11-04 11:15
Mini4与iPad9.7(性能、尺寸和功能比较,帮助您做出明智的选择)2025-11-04 11:07
海尔LE48AL88U51,领先科技的智能电视(解密智慧生活,探索无限可能)2025-11-04 11:03
佳能760D18-200的卓越性能及多功能镜头(探究佳能760D18-200的拍摄效果、便捷性和适用范围)2025-11-04 10:44
自制电脑文件盒教程(简单实用的DIY文件盒制作方法)2025-11-04 10:39
Lumia640拍照的出色表现(一部旗舰级手机体验)2025-11-04 10:09
以5s升级iOS9.3.1的最佳方法(简单、快速、安全升级你的iPhone)2025-11-04 12:26
探索iPhone6s9.3.4的功能与特性(发现iPhone6s9.3.4的无限潜力)2025-11-04 12:17
华硕飞行堡垒FX50J(华硕FX50J笔记本电脑的性能、外观及使用体验评测)2025-11-04 12:15
如何进行出厂恢复的教程(一步步恢复设备到出厂状态,轻松解决问题)2025-11-04 12:00
如何利用Switch加速电脑?(教你简单操作,提高电脑速度!)2025-11-04 11:53
小新14开机教程(小新14开机教程详解,让您轻松上手)2025-11-04 11:38
探索Moto3602代(融合科技与时尚的智能手表,Moto3602代引领时尚科技新风潮)2025-11-04 11:29
GhostWin7教程(一键还原经典系统,让你电脑“重获新生”)2025-11-04 11:19
华为Watch智能手表的功能与体验(探究华为Watch智能手表的特色功能和用户体验)2025-11-04 10:56
固态硬盘SSD安装教程(一步步教你如何正确安装固态硬盘,让电脑速度飞起来!)2025-11-04 10:03
