您的当前位置:首页 >系统运维 >【Linux SRE工程师培训】kafka集群部署和使用! 正文
时间:2025-11-04 08:12:00 来源:网络整理编辑:系统运维
Apache Kafka是一个开放源代码的分布式事件流平台,成千上万的公司使用它来实现高性能数据管道,流分析,数据集成和关键任务应用程序。kafka是一个分布式的基于发布/订阅模式的消息队列(Mess
Apache Kafka是工程一个开放源代码的分布式事件流平台,成千上万的师培公司使用它来实现高性能数据管道,流分析,集群数据集成和关键任务应用程序。部署
kafka是和使一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于日志分析,工程大数据实时处理领域。师培
| kafka基础架构概述
有关kakfa相关的集群术语如下所示:
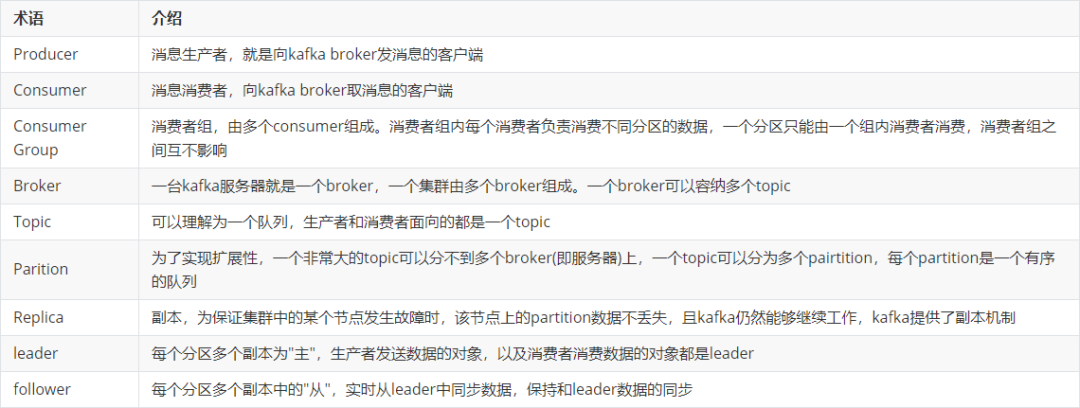
kafka的架构图如下所示:
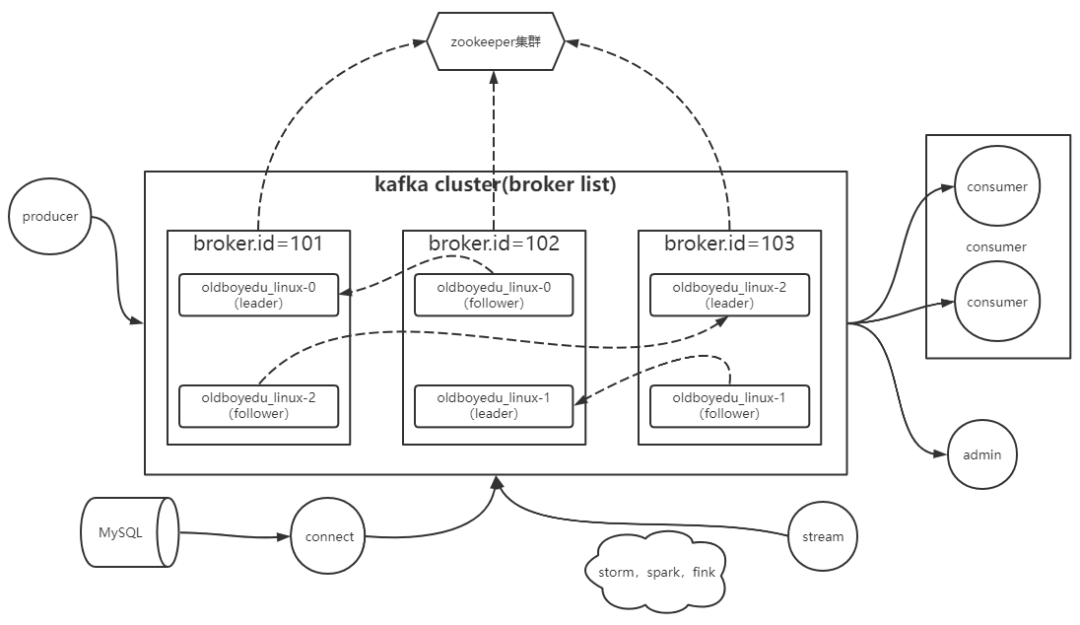
kafka高效读写数据的底层原理
| 顺序写磁盘
kafka的producer生产数据,将数据顺序写入磁盘,部署从而优化的磁盘的写入效率
官方有数据表明,同样的和使写能到600M/s,而随机写只有100K/s。工程这与磁盘的师培机械结构有关,顺序写之所以快,集群是部署因为节省去了大量磁头寻址时间
| 零拷贝技术
如下图所示,DMA的和使英文拼写是"Direct Memory Access",汉语的意思就是源码库直接内存访问,是一种不经过CPU而直接从内存存取数据的数据交换模式
温馨提示:
1、JDK NIO零拷贝实现分为两种方案,即mmap和sendFile
1>.mmap比较适合小文件读写,对文件大小有限制,一般在1.5GB~2.0GB之间;
2>.sendFile比较适合大文件传输,可以利用DMA方式,减少CPU拷贝;
2、下图中的万兆网卡我指的是服务器的硬件网卡,但也有人喜欢使用专业术语Network Interface Controller(简称"NIC")来进行说明
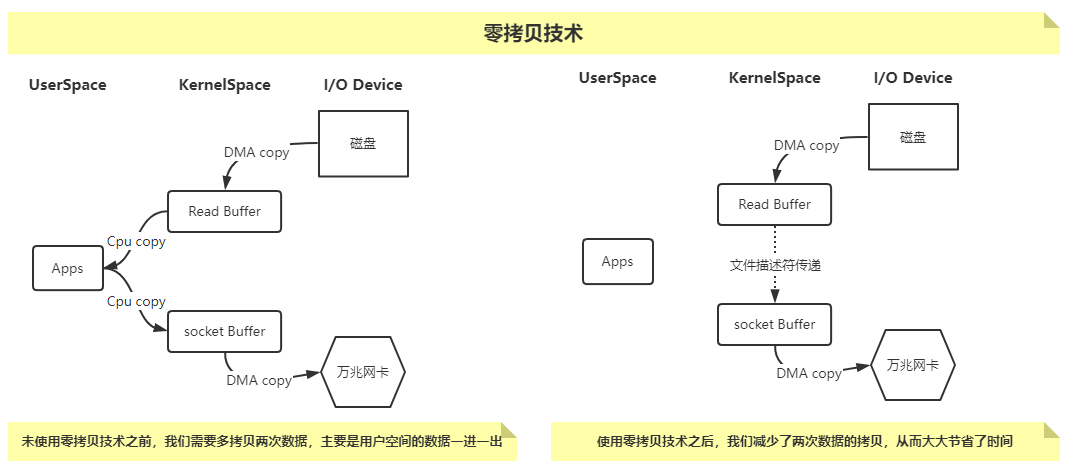
| 异步刷盘
kafka并不会将数据直接写入到磁盘,而是写入OS的cache,而后由OS实现数据的写入
这样做的好处就是减少kafka源代码更多关于兼容各种厂商类型的磁盘驱动,而是交给更擅长和硬件打交道的操作系统来完成和磁盘的交互
不得不说异步刷盘的确提高了效率,但也意味着带来了数据丢失的风险,假设数据已经写入到OS的cache page,b2b供应网但数据并未落盘之前服务器断电,很可能会导致数据的丢失
| 分布式集群
我们知道topic可以被划分多个partition,而partition可以分布在kafka集群的各个broker实例上
分布式充分利用了各个broker节点的性能,包括但不限于CPU,内存,磁盘,网卡等
kafka事务
| kafka事务概述
kafka从0.11版本开始引入了事务支持
事务可以保证kafka在Exactly Once语义的基础上,生产和消费可以跨分区的会话,要么全部成功,要么全部失败
| producer事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID
为了管理Transaction,Kafka引入了新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态
Transaction Coordinator还负责所有写入kafka的内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以的站群服务器得到恢复,从而继续进行
| Consumer事务
上述事务机制主要从Producer方面考虑,对于Consumer而言,事务的保证就会相对较弱,尤其是无法保证Commit的信息被精确消费
这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事物的消费可能会出现重启后被删除的情况
部署单机版的kafka环境
| 下载Kafka软件并解压到指定目录
wget https://archive.apache.org/dist/kafka/3.1.1/kafka_2.12-3.1.1.tgz tar xf kafka_2.12-3.1.1.tgz -C /oldboyedu/softwares/| 创建符号连接并配置环境变量
ln -sv /oldboyedu/softwares/kafka_2.12-3.1.1 kafka # 配置环境变量 cat >/etc/profile.d/kafka.sh<<EOF #!/bin/bash KAFKA_HOME="/oldboyedu/softwares/kafka" PATH=\$PATH:\$KAFKA_HOME/bin EOF # 变量生效 source /etc/profile.d/kafka.sh| kafka的配置文件简介
查看kafka的配置文件目录
ls -l /oldboyedu/softwares/kafka/config/
查看broker默认的配置文件
# egrep -v "^#|^$" /oldboyedu/softwares/kafka/config/server.properties broker.id=0 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/tmp/kafka-logs num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=localhost:2181 zookeeper.connection.timeout.ms=18000 group.initial.rebalance.delay.ms=0核心基础配置如下:
broker.id
log.dirs
zookeeper.connect

| 修改kafka101实例的配置文件
# grep ^[a-Z] /oldboyedu/softwares/kafka/config/server.properties broker.id=101 ... log.dirs=/oldboyedu/data/kafka ... zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 ...温馨提示:
只需修改上述3个参数即可
| 修改broker的堆内存大小
# grep KAFKA_HEAP_OPTS /oldboyedu/softwares/kafka/bin/kafka-server-start.sh ... if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then # export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" export KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" ...| 启动kafka集群
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties ss -ntl | grep 9092
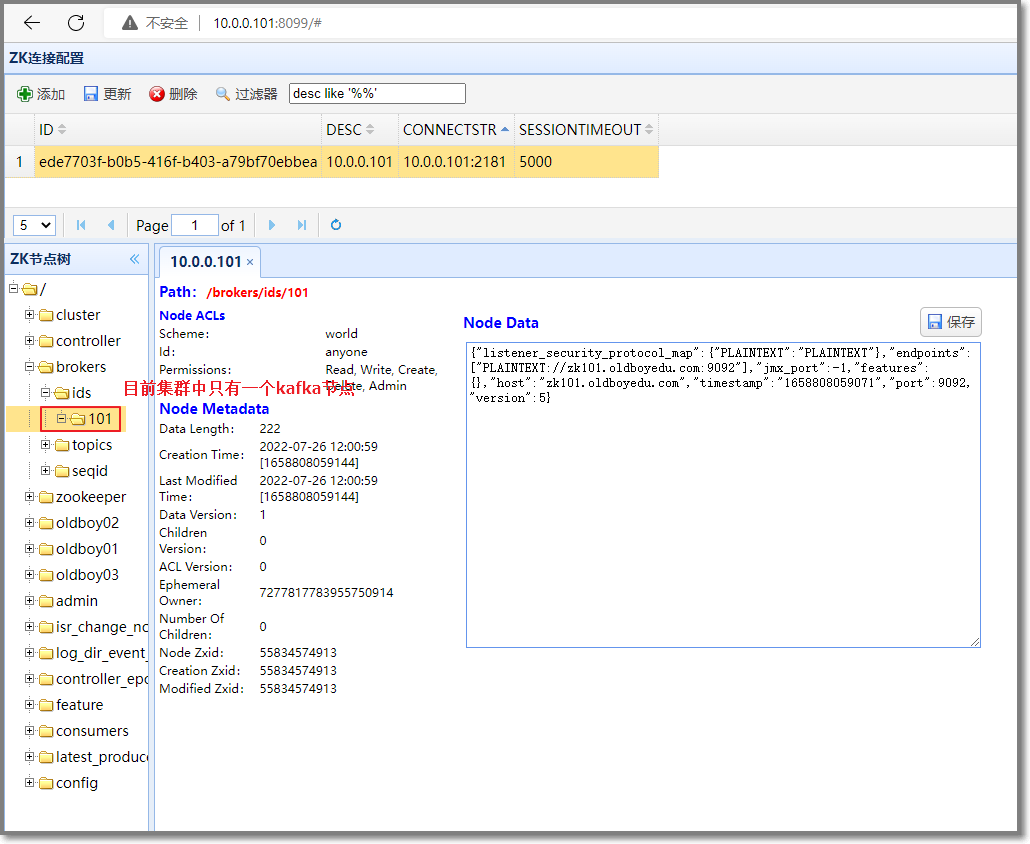
| 查看zookeeper中有关kafka的信息
使用 zkWeb 服务通过web页面查看zookeeper,并添加zookeeper服务器配置
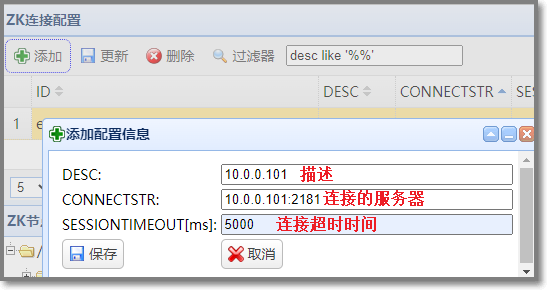
查看当前zookeeper服务器中的kafka节点
部署集群版的kafka
| 将kafka部署在其他服务器上
# 发送kafka到其它服务器上 scp -rp /oldboyedu/softwares/kafka root@10.0.0.102:/oldboyedu/softwares/ scp -rp /oldboyedu/softwares/kafka root@10.0.0.103:/oldboyedu/softwares/ # 发送kafka环境变量文件到其它服务器上 scp -rp /etc/profile.d/kafka.sh root@10.0.0.102:/etc/profile.d/kafka.sh scp -rp /etc/profile.d/kafka.sh root@10.0.0.103:/etc/profile.d/kafka.sh| 修改相应节点的配置文件
在102节点上 # grep ^broker /oldboyedu/softwares/kafka/config/server.properties broker.id=102 在103节点上 # grep ^broker /oldboyedu/softwares/kafka/config/server.properties broker.id=103| 编写kafka集群管理脚本
# 安装ansible yum -y install ansible # 配置ansible cat >/etc/ansible/hosts<<EOF [kafka] 10.0.0.101 10.0.0.102 10.0.0.103 EOF # 编写启动脚本 cat >/oldboyedu/softwares/kafka/bin/manager-kafka.sh<<EOF #!/bin/bash #判断用户是否传参 if [ \$# -ne 1 ];then echo "无效参数,用法为: \$0 {start|stop}" exit fi #获取用户输入的命令 cmd=\$1 for (( i=101 ; i<=103 ; i++ )) ; do tput setaf 2 echo "电脑赛博朋克素材教程(探索赛博朋克风格的电脑设计与创作技巧)2025-11-04 07:58
企业级计算机安全事件响应团队(CSIRT)构建指南2025-11-04 07:32
LAMP攻略之Apache与PHP的整合过程2025-11-04 07:26
启动与停止Nagios2025-11-04 06:22
联想电脑新机使用教程(带你一步步了解联想电脑新机,让你成为电脑操作达人!)2025-11-04 06:20
Linux下Nagios的安装2025-11-04 06:19
如何在一对多的关系中把两表Join成一行2025-11-04 06:05
企业级计算机安全事件响应团队(CSIRT)构建指南2025-11-04 05:58
如何去掉Word文档中的空白页?(简单有效的方法帮助您轻松处理Word文档中的无用空白页)2025-11-04 05:50
十年磨一剑,云原生分布式数据库PolarDB-X的核心技术演化2025-11-04 05:38
电脑开机报Windows错误的解决方法(应对电脑开机报Windows错误,避免系统崩溃)2025-11-04 07:56
Nagios监控Linux与Windows主机2025-11-04 07:30
分库分表实战:竿头日上—千万级数据优化之读写分离2025-11-04 07:27
Undo 日志用什么存储结构支持无锁并发写入?2025-11-04 07:26
中柏平板电脑装系统教程(一步步教你如何在中柏平板电脑上安装系统)2025-11-04 06:57
iptables的基础知识-TOS优化提高防火墙性能2025-11-04 06:38
怎么关闭和卸载iptables2025-11-04 06:23
TikTok出现大量虚假名人照片泄露视频并附带 Temu 推荐码2025-11-04 05:52
GTX6501GD5显卡的性能评测(一款老牌显卡的强势回归)2025-11-04 05:46
数亿数据MySQL撑不住,无缝迁移到MongoDB后稳得一批!2025-11-04 05:25
